Deduplication trong lưu trữ dữ liệu sao lưu là gì?
Các hạ tầng ảo quy mô lớn ngày nay tạo ra một lượng dữ liệu khổng lồ. Điều này dẫn đến sự gia tăng về khối lượng dữ liệu sao lưu cũng như chi phí cho hạ tầng lưu trữ sao lưu, bao gồm các thiết bị lưu trữ và chi phí bảo trì của chúng. Vì lý do này, các quản trị viên mạng đang tìm kiếm các giải pháp để tiết kiệm không gian lưu trữ khi thực hiện sao lưu thường xuyên cho các máy chủ và ứng dụng quan trọng.
Một trong những kỹ thuật được sử dụng rộng rãi là loại bỏ trùng lặp dữ liệu sao lưu. Bài viết này sẽ giải thích khái niệm về loại bỏ trùng lặp dữ liệu, các loại hình loại bỏ trùng lặp, cùng các trường hợp ứng dụng, với trọng tâm là trong lĩnh vực sao lưu.

Deduplication là gì?
Deduplication là một công nghệ tối ưu hóa dung lượng lưu trữ. Quá trình deduplication bao gồm việc đọc dữ liệu nguồn và dữ liệu đã có trong hệ thống lưu trữ để chỉ chuyển hoặc lưu trữ các khối dữ liệu duy nhất. Các tham chiếu đến dữ liệu trùng lặp vẫn được duy trì. Bằng cách sử dụng công nghệ này để loại bỏ dữ liệu trùng lặp trên một khối lượng lưu trữ, bạn có thể tiết kiệm không gian đĩa và giảm thiểu chi phí lưu trữ.
Nguồn gốc của công nghệ loại bỏ dữ liệu trùng lặp
Tiền thân của công nghệ loại bỏ dữ liệu trùng lặp là các thuật toán nén LZ77 và LZ78 được giới thiệu lần lượt vào năm 1977 và 1978. Chúng bao gồm việc thay thế các chuỗi dữ liệu lặp lại bằng các tham chiếu đến các chuỗi gốc.
Khái niệm này đã ảnh hưởng đến các phương pháp nén phổ biến khác. Phương pháp nổi tiếng nhất trong số này là DEFLATE, được sử dụng trong định dạng hình ảnh PNG và tệp ZIP. Bây giờ hãy xem cách hoạt động của việc loại bỏ dữ liệu trùng lặp với bản sao lưu VM và cách nó giúp tiết kiệm không gian lưu trữ và chi phí cho hạ tầng.
Loại bỏ dữ liệu trùng lặp trong sao lưu là gì?
Trong quá trình sao lưu, việc loại bỏ dữ liệu trùng lặp kiểm tra các khối dữ liệu giống hệt nhau giữa lưu trữ nguồn và kho lưu trữ sao lưu đích. Các bản sao trùng lặp không được sao chép, và một tham chiếu (hoặc chỉ mục) đến các khối dữ liệu hiện có trong kho lưu trữ sao lưu đích được tạo ra.

Deduplication có thể giúp tiết kiệm bao nhiêu dung lượng lưu trữ?
Để hiểu rõ lượng dung lượng lưu trữ có thể tiết kiệm được nhờ deduplication, hãy xem xét một ví dụ. Yêu cầu hệ thống tối thiểu để cài đặt {4} là ít nhất 32 GB dung lượng đĩa trống. Nếu bạn có mười máy ảo (VM) chạy hệ điều hành này, tổng dung lượng sao lưu sẽ là ít nhất 320 GB, và đây chỉ là hệ điều hành sạch sẽ, không có ứng dụng hay cơ sở dữ liệu nào trên đó.
Khả năng cao là nếu bạn cần triển khai hơn một máy ảo ( máy ảo ) với cùng hệ thống, bạn sẽ sử dụng một mẫu (template), và điều này có nghĩa là ban đầu, bạn sẽ có mười máy giống hệt nhau. Điều này cũng có nghĩa là bạn sẽ có 10 bộ khối dữ liệu trùng lặp. Trong ví dụ này, bạn sẽ có tỷ lệ tiết kiệm không gian lưu trữ là 10:1. Nhìn chung, tỷ lệ tiết kiệm từ 5:1 đến 10:1 được coi là tốt.
Tỷ lệ loại bỏ dữ liệu trùng lặp
Tỷ lệ loại bỏ dữ liệu trùng lặp là một chỉ số được sử dụng để đo lường kích thước dữ liệu ban đầu so với kích thước dữ liệu sau khi các phần dư thừa được loại bỏ. Chỉ số này cho phép bạn đánh giá hiệu quả của quá trình loại bỏ dữ liệu trùng lặp. Để tính toán giá trị này, bạn nên chia lượng dữ liệu trước khi loại bỏ trùng lặp cho dung lượng lưu trữ mà dữ liệu này chiếm dụng sau khi được loại bỏ trùng lặp. Ví dụ, tỷ lệ loại trừ trùng lặp 5:1 có nghĩa là bạn có thể lưu trữ lượng dữ liệu sao lưu gấp năm lần trong kho lưu trữ so với lượng cần thiết để lưu trữ cùng một lượng dữ liệu đó mà không áp dụng loại trừ trùng lặp.
Bạn nên xác định deduplication ratio và storage space reduction. Hai thông số này đôi khi bị nhầm lẫn. Tỷ lệ loại trừ trùng lặp không thay đổi tỷ lệ thuận với lợi ích giảm dung lượng dữ liệu, vì quy luật lợi nhuận giảm dần sẽ bắt đầu phát huy tác dụng khi vượt qua một ngưỡng nhất định. Xem biểu đồ bên dưới.

Điều này có nghĩa là các tỷ lệ thấp hơn có thể mang lại tiết kiệm đáng kể hơn so với tỷ lệ cao hơn. Ví dụ, tỷ lệ loại trừ trùng lặp 50:1 không tốt hơn gấp năm lần so với tỷ lệ 10:1. Tỷ lệ 10:1 giảm 90% dung lượng lưu trữ tiêu thụ, trong khi tỷ lệ 50:1 tăng giá trị này lên 98%, vì phần lớn sự trùng lặp đã được loại bỏ. Để biết thêm thông tin về cách tính các tỷ lệ phần trăm này, bạn có thể xem {7} Tài liệu về loại bỏ dữ liệu trùng lặp.
Các yếu tố ảnh hưởng đến hiệu quả nén dữ liệu
Rất khó để dự đoán hiệu quả nén dữ liệu cho đến khi dữ liệu thực sự được nén do nhiều yếu tố. Dưới đây là một số yếu tố ảnh hưởng đến việc nén dữ liệu khi sử dụng nén dữ liệu:
- Các loại sao lưu dữ liệu và chính sách . Nén dữ liệu cho sao lưu toàn bộ hiệu quả hơn so với từng bước hoặc phân biệt sao lưu.
- Tỷ lệ thay đổi . Nếu có nhiều thay đổi dữ liệu cần sao lưu, tỷ lệ loại trừ trùng lặp sẽ thấp hơn.
- Cài đặt lưu trữ . Thời gian lưu trữ bản sao lưu dữ liệu trong kho lưu trữ càng lâu, hiệu quả của việc loại trừ trùng lặp dữ liệu trên kho lưu trữ đó càng cao.
- Loại dữ liệu . Việc loại trừ trùng lặp đối với các tệp đã được nén sẵn, chẳng hạn như
JPG, PNG, MPG, AVI, MP4, ZIP, RAR, v.v., không hiệu quả. Điều này cũng áp dụng cho dữ liệu chứa nhiều metadata và dữ liệu được mã hóa. Các loại dữ liệu chứa các phần lặp lại sẽ phù hợp hơn cho việc loại trừ trùng lặp. - Phạm vi dữ liệu . Việc loại bỏ dữ liệu trùng lặp hiệu quả hơn khi áp dụng cho phạm vi dữ liệu lớn. Loại bỏ dữ liệu trùng lặp toàn cục có thể tiết kiệm nhiều không gian lưu trữ hơn so với loại bỏ dữ liệu trùng lặp cục bộ.
Lưu ý: Loại bỏ dữ liệu trùng lặp cục bộ hoạt động trên một nút/thiết bị đĩa duy nhất. Loại bỏ dữ liệu trùng lặp toàn cục phân tích toàn bộ tập dữ liệu trên tất cả các nút/thiết bị đĩa để loại bỏ dữ liệu trùng lặp. Nếu bạn có nhiều nút với tính năng loại bỏ dữ liệu trùng lặp cục bộ được bật trên mỗi nút, việc loại bỏ dữ liệu trùng lặp sẽ không hiệu quả bằng khi bật tính năng loại bỏ dữ liệu trùng lặp toàn cục cho chúng.
- Phần mềm và phần cứng. Việc kết hợp các giải pháp phần mềm với thiết bị phần cứng chống trùng lặp có thể mang lại tỷ lệ chống trùng lặp cao hơn so với chỉ sử dụng phần mềm. Ví dụ, giải pháp sao lưu của NAKIVO cung cấp các thiết bị chống trùng lặp tích hợp với {9},
Dell EMC Data Domain, vàNEC HYDRAstorvới tỷ lệ chống trùng lặp lên đến 17:1.
Các kỹ thuật loại trừ dữ liệu sao lưu
Các kỹ thuật loại trừ dữ liệu sao lưu có thể được phân loại dựa trên các tiêu chí sau:
- Vị trí thực hiện loại trừ dữ liệu
- Thời điểm thực hiện loại trừ dữ liệu
- Cách thức thực hiện loại trừ dữ liệu
Vị trí thực hiện loại trừ dữ liệu
Loại trừ dữ liệu sao lưu có thể được thực hiện ở phía nguồn hoặc phía đích, và các kỹ thuật này lần lượt được gọi là loại trừ dữ liệu phía nguồn và loại trừ dữ liệu phía đích.
Loại bỏ trùng lặp phía nguồn
Loại bỏ trùng lặp phía nguồn giảm tải mạng vì ít dữ liệu được truyền trong quá trình sao lưu. Tuy nhiên, nó yêu cầu cài đặt trình điều khiển loại bỏ trùng lặp trên mỗi máy ảo (VM) hoặc trên mỗi máy chủ. Nhược điểm khác là loại bỏ trùng lặp phía nguồn có thể giảm tốc độ các máy ảo do các tính toán cần thiết để xác định các khối dữ liệu trùng lặp.

Loại bỏ trùng lặp phía đích
Loại bỏ trùng lặp phía đích trước tiên chuyển dữ liệu đến kho lưu trữ sao lưu rồi mới thực hiện loại bỏ trùng lặp. Các tác vụ tính toán nặng được thực hiện bởi phần mềm chịu trách nhiệm về việc loại trừ trùng lặp.
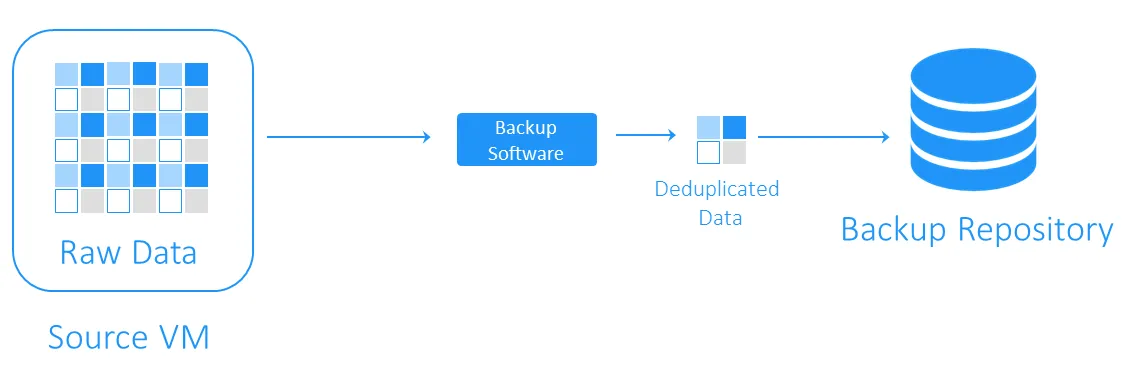
Khi quá trình loại trừ trùng lặp dữ liệu hoàn tất
Loại trừ trùng lặp sao lưu có thể là trực tuyến hoặc sau xử lý.
- Loại trừ trùng lặp trực tuyến kiểm tra dữ liệu trùng lặp trước khi ghi vào kho lưu trữ sao lưu. Kỹ thuật này yêu cầu ít không gian lưu trữ hơn trong kho lưu trữ sao lưu vì nó loại bỏ các phần dư thừa khỏi luồng dữ liệu sao lưu, nhưng nó dẫn đến thời gian sao lưu lâu hơn vì quá trình loại trừ trùng lặp trực tuyến diễn ra trong quá trình thực hiện công việc sao lưu.
- Loại bỏ trùng lặp sau xử lý xử lý dữ liệu sau khi dữ liệu được ghi vào kho lưu trữ sao lưu. Rõ ràng, phương pháp này yêu cầu nhiều dung lượng trống hơn trong kho lưu trữ, nhưng quá trình sao lưu diễn ra nhanh hơn và tất cả các thao tác cần thiết được thực hiện sau đó. Loại bỏ trùng lặp sau xử lý còn được gọi là loại bỏ trùng lặp không đồng bộ.
Cách thức thực hiện loại bỏ trùng lặp dữ liệu
Các phương pháp phổ biến nhất để xác định dữ liệu trùng lặp là phương pháp dựa trên hàm băm và phương pháp dựa trên hàm băm đã sửa đổi.
- Với phương pháp dựa trên hàm băm , phần mềm loại bỏ trùng lặp chia dữ liệu thành các khối có độ dài cố định hoặc thay đổi và tính toán hàm băm cho từng khối bằng các thuật toán mật mã như
MD5, SHA-1,hoặcSHA-256. Mỗi phương pháp này tạo ra một dấu vân tay duy nhất cho các khối dữ liệu, do đó các khối có hàm băm tương tự được coi là giống hệt nhau. Nhược điểm của phương pháp này là có thể đòi hỏi nguồn lực tính toán đáng kể, đặc biệt trong trường hợp các bản sao lưu có dung lượng lớn. - Phương pháp dựa trên hàm băm đã được điều chỉnh tại sử dụng các thuật toán tạo hàm băm đơn giản hơn như
CRC, chỉ tạo ra 16 bit (so với 256 bit trongSHA-256). Sau đó, nếu các khối có các giá trị băm tương tự, chúng sẽ được so sánh từng byte. Nếu chúng hoàn toàn giống nhau, các khối được coi là giống hệt nhau. Phương pháp này chậm hơn một chút so với phương pháp dựa trên hàm băm nhưng yêu cầu ít tài nguyên tính toán hơn.
Lựa chọn phần mềm loại bỏ trùng lặp sao lưu
Loại bỏ trùng lặp sao lưu là một trong những trường hợp sử dụng phổ biến nhất của công nghệ loại bỏ trùng lặp. Tuy nhiên, bạn cần có giải pháp phần mềm phù hợp và hạ tầng lưu trữ để triển khai công nghệ giảm dung lượng dữ liệu này.
NAKIVO Backup & Replication là giải pháp sao lưu hỗ trợ sử dụng công nghệ loại bỏ trùng lặp sau xử lý trên mục tiêu toàn cầu kết hợp với phát hiện trùng lặp dựa trên băm đã được điều chỉnh. Bạn cũng có thể tận dụng tính năng loại bỏ trùng lặp phía nguồn bằng cách tích hợp các thiết bị loại bỏ trùng lặp như {16} cùng với {17}, NEC HYDRAstor và HP StoreOnce với hỗ trợ Catalyst thông qua giải pháp NAKIVO.



