Giới thiệu về Amazon S3: Cách thức hoạt động của dịch vụ lưu trữ đối tượng trên đám mây
Amazon Simple Storage Service (S3) là một dịch vụ lưu trữ đám mây phổ biến thuộc hệ sinh thái Amazon Web Services (AWS). Dịch vụ lưu trữ đám mây Amazon S3 mang lại độ tin cậy cao, tính linh hoạt, khả năng mở rộng và khả năng truy cập thuận tiện. Số lượng đối tượng và dung lượng dữ liệu lưu trữ trên Amazon S3 là không giới hạn. Dịch vụ lưu trữ đám mây S3 rất hấp dẫn đối với doanh nghiệp vì bạn chỉ phải trả tiền cho những gì bạn sử dụng.
Tuy nhiên, thuật ngữ và phương pháp luận có thể dẫn đến sự hiểu lầm và khó khăn cho những người mới sử dụng Amazon S3. Dữ liệu S3 được lưu trữ ở đâu? Dịch vụ lưu trữ Amazon S3 hoạt động như thế nào? Bài đăng trên blog này giải thích các khái niệm chính và nguyên tắc hoạt động của dịch vụ lưu trữ đám mây Amazon S3.

Giới thiệu về dịch vụ lưu trữ Amazon S3
Amazon S3 là dịch vụ đám mây đầu tiên của AWS, ra mắt vào năm 2006. Kể từ đó, dịch vụ lưu trữ này ngày càng trở nên phổ biến. Hiện nay, Amazon cung cấp một danh sách đa dạng các dịch vụ đám mây khác, nhưng dịch vụ lưu trữ đám mây Amazon S3 vẫn là dịch vụ được sử dụng rộng rãi nhất. Ngoài dịch vụ lưu trữ Amazon S3, AWS còn cung cấp các khối lượng lưu trữ Amazon EBS dành cho EC2 và Amazon Drive. Tuy nhiên, ba dịch vụ này có mục đích và ứng dụng khác nhau.
EBS (Elastic Block Storage) các khối lượng EBS dành cho các phiên bản EC2 (Elastic Compute Cloud) là các đĩa ảo dành cho máy ảo nằm trong đám mây Amazon. Như tên gọi EBS đã gợi ý, đây là dịch vụ lưu trữ khối trên đám mây, tương đương với các ổ cứng trong máy tính vật lý. Hệ điều hành có thể được cài đặt trên một khối lượng EBS được gắn vào một EC2 phiên bản.
Amazon Drive (trước đây gọi là Amazon Cloud Drive) là dịch vụ tương tự như Google Drive và Microsoft OneDrive. Amazon Drive có phạm vi tính năng hẹp hơn so với Amazon S3. Amazon Drive được định vị là dịch vụ lưu trữ trên đám mây để sao lưu ảnh và dữ liệu người dùng khác.
Amazon S3 lưu trữ đám mây là dịch vụ lưu trữ dựa trên đối tượng. Bạn không thể cài đặt hệ điều hành khi sử dụng lưu trữ Amazon S3 vì dữ liệu không thể truy cập ở cấp độ khối như yêu cầu của hệ điều hành. Nếu bạn cần gắn kết lưu trữ Amazon S3 dưới dạng ổ đĩa mạng vào hệ điều hành của mình, hãy sử dụng hệ thống tệp trong không gian người dùng. Đọc bài đăng trên blog về Kết nối dịch vụ lưu trữ đám mây S3 cho các hệ điều hành khác nhau. Google Cloud là phiên bản tương tự của dịch vụ lưu trữ đám mây Amazon S3.
Các khái niệm chính của Amazon S3
Nếu bạn định sử dụng Amazon S3 lần đầu tiên, một số khái niệm có thể khá lạ lẫm và xa lạ với bạn. Phương pháp lưu trữ dữ liệu trên đám mây S3 khác với việc lưu trữ dữ liệu trên các ổ cứng truyền thống, ổ SSD hoặc mảng đĩa. Dưới đây là tổng quan về các khái niệm và công nghệ chính được sử dụng để lưu trữ và quản lý dữ liệu trong dịch vụ lưu trữ đám mây Amazon S3.
Cách S3 lưu trữ tệp tin?
Như đã giải thích ở trên, dữ liệu trong Amazon S3 được lưu trữ dưới dạng các đối tượng. Phương pháp này cung cấp khả năng mở rộng cao trong môi trường đám mây. Các đối tượng có thể được đặt trên các ổ đĩa vật lý khác nhau phân tán khắp trung tâm dữ liệu. Phần cứng, phần mềm và hệ thống tệp phân tán đặc biệt được sử dụng trong các trung tâm dữ liệu của Amazon để cung cấp khả năng mở rộng cao. Tính dự phòng và tạo phiên bản là các tính năng được triển khai bằng cách sử dụng phương pháp lưu trữ khối. Khi một tệp được lưu trữ trong Amazon S3 dưới dạng đối tượng, theo mặc định, tệp đó sẽ được lưu trữ đồng thời ở nhiều nơi (chẳng hạn như trên đĩa, trong trung tâm dữ liệu hoặc vùng sẵn sàng). Dịch vụ Amazon S3 thường xuyên kiểm tra tính nhất quán của dữ liệu bằng cách đối chiếu các tổng kiểm tra (control hash sums). Nếu phát hiện dữ liệu bị hỏng, đối tượng sẽ được khôi phục bằng cách sử dụng dữ liệu dự phòng. Các đối tượng được lưu trữ trong các thùng (bucket) của Amazon S3. Theo mặc định, các đối tượng trong kho lưu trữ Amazon S3 có thể được truy cập và quản lý thông qua giao diện web.
Lưu trữ đối tượng S3 là gì?
Lưu trữ đối tượng là một loại lưu trữ trong đó dữ liệu được lưu trữ dưới dạng các đối tượng thay vì các khối. Khái niệm này hữu ích cho việc lưu trữ dữ liệu sao lưu, lưu trữ lâu dài và khả năng mở rộng cho các môi trường có tải cao.
Objects là các thực thể cơ bản của lưu trữ dữ liệu trong các thùng Amazon S3. Có ba thành phần chính của một đối tượng – nội dung của đối tượng (dữ liệu được lưu trữ trong đối tượng như tệp hoặc thư mục), mã định danh duy nhất của đối tượng (ID) và siêu dữ liệu. Siêu dữ liệu được lưu trữ dưới dạng các cặp khóa-giá trị và chứa thông tin như tên, kích thước, ngày tháng, thuộc tính bảo mật, loại nội dung và URL.
Mỗi đối tượng có một danh sách kiểm soát truy cập (ACL) để cấu hình ai được phép truy cập đối tượng đó. Lưu trữ đối tượng Amazon S3 cho phép bạn tránh tắc nghẽn mạng vào giờ cao điểm khi lưu lượng truy cập đến các đối tượng của bạn được lưu trữ trên lưu trữ đám mây S3 tăng lên đáng kể. Amazon cung cấp băng thông mạng linh hoạt nhưng tính phí cho việc truy cập mạng vào các đối tượng được lưu trữ. Lưu trữ đối tượng là lựa chọn tốt khi có số lượng lớn khách hàng cần truy cập dữ liệu (tần suất đọc cao). Tìm kiếm qua metadata nhanh hơn trong mô hình lưu trữ đối tượng.
Đọc thêm về Mã hóa Amazon S3 để giúp bạn bảo vệ dữ liệu lưu trữ trên lưu trữ đám mây Amazon S3 và nâng cao bảo mật.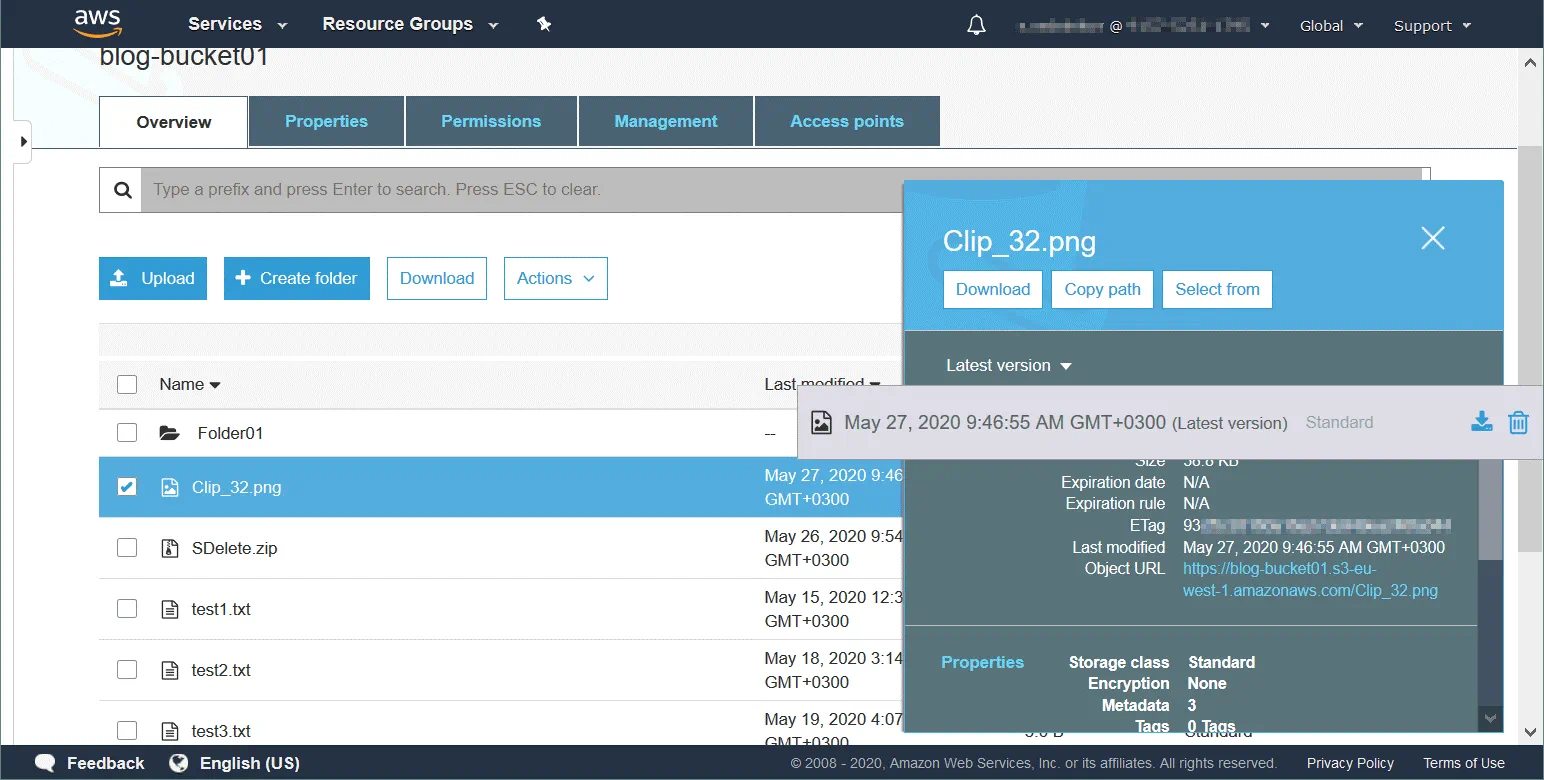
Buckets
A bucket là container logic cơ bản nơi dữ liệu được lưu trữ trong lưu trữ Amazon S3. Bạn có thể lưu trữ một lượng dữ liệu vô hạn và số lượng đối tượng không giới hạn trong một bucket. Mỗi đối tượng S3 được lưu trữ trong một bucket. Có giới hạn 5 TB cho kích thước của một đối tượng được lưu trữ trong một bucket. Buckets được sử dụng để tổ chức không gian tên ở cấp cao nhất và được sử dụng cho kiểm soát truy cập.
Keys
Một đối tượng có một unique key sau khi đã được tải lên một bucket. Khóa này là một chuỗi ký tự mô phỏng cấu trúc thư mục. Biết được khóa sẽ cho phép bạn truy cập đối tượng trong bucket. Một bucket, khóa và ID phiên bản xác định một đối tượng một cách duy nhất. Ví dụ: nếu tên bucket là blog-bucket01 , khu vực nơi các trung tâm dữ liệu lưu trữ dữ liệu của bạn nằm ở s3-eu-west-1 và tên đối tượng là test1.txt (một tệp văn bản), thì URL đến tệp cần thiết được lưu trữ dưới dạng đối tượng trong bucket là: https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Nếu muốn chia sẻ các đối tượng với người dùng khác, bạn phải cấu hình quyền truy cập bằng cách chỉnh sửa thuộc tính của đối tượng. Tương tự, bạn có thể tạo một thư mục TextFiles và lưu tệp văn bản vào thư mục đó:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
Có hai loại URL có thể được sử dụng:
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/objectname
Các khu vực AWS
Amazon có các trung tâm dữ liệu ở nhiều khu vực khác nhau trên toàn cầu, bao gồm Mỹ, Ireland, Nam Phi, Ấn Độ, Nhật Bản, Trung Quốc, Hàn Quốc, Canada, Đức, Ý và Anh. Bạn có thể chọn khu vực mong muốn khi tạo bucket. Nên chọn khu vực gần nhất với bạn hoặc khách hàng của bạn để giảm độ trễ kết nối mạng hoặc tiết kiệm chi phí (vì giá lưu trữ dữ liệu khác nhau tùy theo khu vực). Dữ liệu được lưu trữ trong một khu vực AWS cụ thể sẽ không bao giờ rời khỏi các trung tâm dữ liệu của khu vực đó cho đến khi bạn di chuyển dữ liệu thủ công. Các khu vực AWS được cách ly với nhau để đảm bảo khả năng chịu lỗi và tính ổn định.
Mỗi khu vực chứa các Khu vực sẵn sàng (Availability Zones), là các vị trí cách ly bên trong một khu vực AWS. Mỗi khu vực có ít nhất ba Khu vực sẵn sàng để ngăn chặn sự cố do thảm họa như hỏa hoạn, bão, lốc xoáy, lũ lụt, v.v.
Mô hình nhất quán dữ liệu
Kiểm tra nhất quán “đọc sau khi ghi” được thực hiện đối với các đối tượng lưu trữ trong Amazon S3. Amazon S3 sao chép dữ liệu qua các máy chủ và trung tâm dữ liệu trong khu vực đã chọn để đạt được tính sẵn sàng cao. Sau khi yêu cầu PUT thành công, dữ liệu đã thay đổi phải được sao chép trên các máy chủ. Quá trình này có thể mất một chút thời gian. Trong trường hợp này, người dùng có thể nhận được dữ liệu cũ hoặc dữ liệu đã cập nhật, nhưng không phải dữ liệu bị hỏng. Điều này cũng áp dụng cho các đối tượng và bucket đã bị xóa. Khóa đối tượng không được thực hiện khi các đối tượng mới được gửi đến các bucket S3. Yêu cầu PUT mới nhất sẽ được ưu tiên nếu nhiều yêu cầu PUT được thực hiện đồng thời. Bạn có thể tạo ứng dụng của riêng mình với cơ chế khóa hoạt động với các đối tượng được lưu trữ trong bộ nhớ Amazon S3.
Các tính năng của Amazon S3
Khái niệm lưu trữ dựa trên đối tượng cho phép Amazon cung cấp các tính năng hữu ích và tính linh hoạt cao để lưu trữ và quản lý dữ liệu trong bộ nhớ Amazon S3. Hãy cùng xem xét các tính năng này.
Quản lý phiên bản
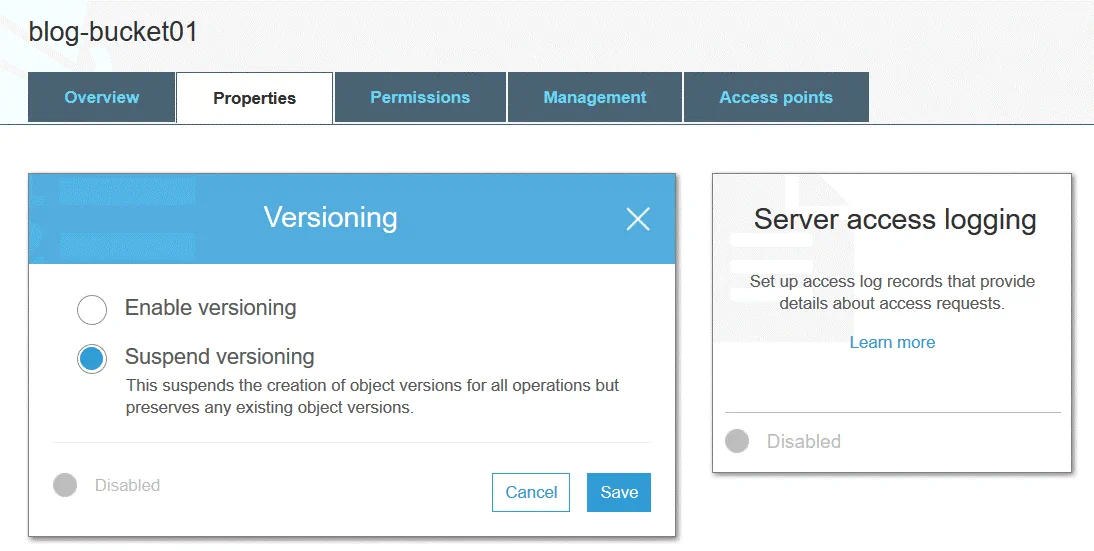
Tính năng quản lý phiên bản đối tượng cho phép bạn lưu trữ nhiều phiên bản của một đối tượng trong cùng một bucket. Tính năng này giúp bảo vệ các đối tượng được lưu trữ trên Amazon S3 khỏi các thao tác chỉnh sửa, ghi đè hoặc xóa nhầm. Sau khi thay đổi hoặc xóa một đối tượng, bạn có thể khôi phục lại một trong các phiên bản trước đó của đối tượng đó. Tính năng quản lý phiên bản được triển khai nhờ việc áp dụng phương pháp lưu trữ đối tượng. Bạn có thể sử dụng quản lý phiên bản cho mục đích lưu trữ. Tính năng này bị tắt theo mặc định.
Mỗi đối tượng S3 đều được gán một ID phiên bản ngay cả khi tính năng quản lý phiên bản không được bật (trong trường hợp này, giá trị ID phiên bản được đặt là null). Nếu tính năng quản lý phiên bản được bật, một giá trị ID phiên bản mới sẽ được gán cho phiên bản mới của đối tượng sau khi ghi các thay đổi. Tính năng quản lý phiên bản có thể được bật ở cấp độ thùng chứa. Giá trị ID phiên bản của phiên bản đầu tiên của đối tượng vẫn giữ nguyên. Khi bạn xóa một đối tượng khỏi thùng S3 (với tính năng phiên bản được bật), dấu xóa sẽ được áp dụng cho phiên bản mới nhất của đối tượng.
Các lớp lưu trữ
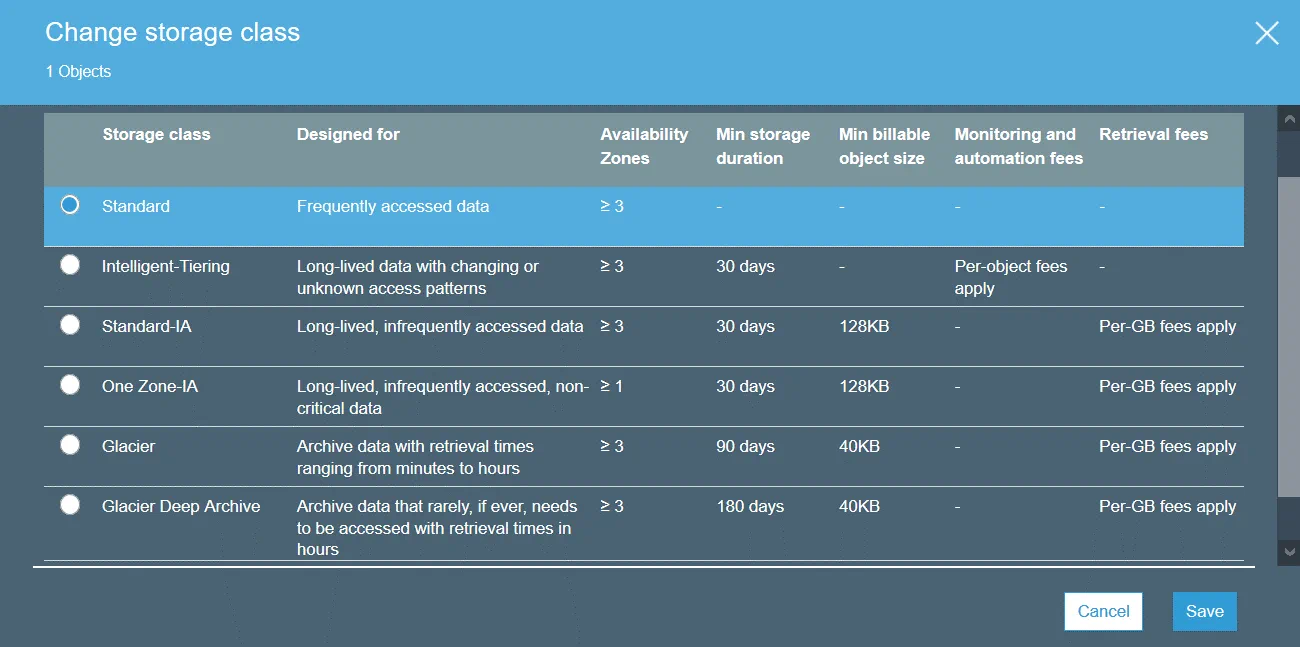
Các lớp lưu trữ Amazon S3 xác định mục đích của không gian lưu trữ được chọn để lưu trữ dữ liệu. Một lớp lưu trữ có thể được thiết lập ở cấp độ đối tượng. Tuy nhiên, bạn có thể thiết lập lớp lưu trữ mặc định cho các đối tượng sẽ được tạo ở cấp độ thùng.
S3 Standard là lớp lưu trữ mặc định. Lớp này là lưu trữ dữ liệu nóng và phù hợp cho dữ liệu được sử dụng thường xuyên. Sử dụng lớp lưu trữ Standard để lưu trữ trang web, phân phối nội dung, phát triển ứng dụng đám mây, v.v. Chi phí lưu trữ cao, chi phí khôi phục thấp và truy cập dữ liệu nhanh là các tính năng của lớp lưu trữ này.
S3 Standard-IA (truy cập không thường xuyên) có thể được sử dụng để lưu trữ dữ liệu được truy cập ít thường xuyên hơn so với S3 Standard. S3 Standard-IA được tối ưu hóa cho thời gian lưu trữ dài hơn. Có phí khi truy xuất dữ liệu được lưu trữ trong lớp lưu trữ S3 Standard-IA. Ngoài ra, trong cả S3 Standard và S3 Standard-IA bạn phải trả phí cho các yêu cầu dữ liệu (PUT, COPY, POST, LIST, GET, SELECT).
S3 One Zone-IA được thiết kế cho dữ liệu ít được truy cập. Dữ liệu chỉ được lưu trữ trong một vùng sẵn sàng (dữ liệu được lưu trữ trong ba vùng sẵn sàng đối với S3 Standard) và do đó, mức độ dự phòng và khả năng phục hồi thấp hơn. Mức độ sẵn sàng được công bố là 99,5%, thấp hơn so với hai lớp lưu trữ còn lại. S3 One Zone-IA có chi phí lưu trữ thấp hơn, chi phí khôi phục cao hơn và bạn phải trả phí cho việc truy xuất dữ liệu theo đơn vị GB. Bạn có thể xem xét sử dụng lớp lưu trữ này như một giải pháp tiết kiệm chi phí để lưu trữ dữ liệu bản sao lưu hoặc các bản sao dữ liệu được tạo ra thông qua tính năng sao chép liên vùng của Amazon S3.
S3 Glacier không cung cấp quyền truy cập tức thì vào dữ liệu đã lưu trữ, khác với các lớp lưu trữ khác. S3 Glacier có thể được sử dụng để lưu trữ dữ liệu cho mục đích lưu trữ dài hạn với chi phí thấp. Không có đảm bảo về việc hoạt động liên tục. Bạn cần chờ từ vài phút đến vài giờ để truy xuất dữ liệu. Bạn có thể chuyển dữ liệu cũ từ lớp lưu trữ cao hơn (ví dụ: từ S3 Standard) sang S3 Glacier bằng cách sử dụng chính sách vòng đời S3 và giảm chi phí lưu trữ.
S3 Glacier Deep Archive tương tự như S3 Glacier, nhưng thời gian cần thiết để truy xuất dữ liệu là khoảng 12 giờ đến 48 giờ. Giá cả thấp hơn so với S3 Glacier. Lớp lưu trữ S3 Glacier Deep Archive có thể được sử dụng để lưu trữ bản sao lưu và dữ liệu lưu trữ của các công ty tuân thủ các yêu cầu quy định về lưu trữ dữ liệu (tài chính, y tế). Đây là một giải pháp thay thế tốt cho băng từ.
S3 Intelligent-Tiering là một lớp lưu trữ đặc biệt sử dụng các lớp lưu trữ khác. S3 Intelligent-Tiering được thiết kế để tự động chọn lớp lưu trữ phù hợp hơn để lưu trữ dữ liệu khi bạn không biết tần suất truy cập dữ liệu này. Amazon S3 có thể theo dõi các mẫu truy cập dữ liệu khi sử dụng S3 Intelligent-Tiering, sau đó lưu trữ các đối tượng trong một trong hai lớp lưu trữ được chọn (một lớp dành cho dữ liệu được truy cập thường xuyên và một lớp dành cho dữ liệu ít được truy cập). Cách tiếp cận này mang lại hiệu quả chi phí tối ưu mà không ảnh hưởng đến hiệu suất.
Ví dụ: nếu bạn truy cập một đối tượng được lưu trữ trong lớp lưu trữ dành cho dữ liệu ít được truy cập, đối tượng này sẽ tự động được chuyển sang lớp lưu trữ dành cho dữ liệu được truy cập thường xuyên. Ngược lại, nếu một đối tượng không được truy cập trong thời gian dài, đối tượng đó sẽ được chuyển sang lớp lưu trữ dành cho dữ liệu ít được sử dụng. Các đối tượng có thể nằm trong cùng một bucket và lớp lưu trữ được thay đổi ở cấp độ đối tượng S3.
Danh sách kiểm soát truy cập (ACL)
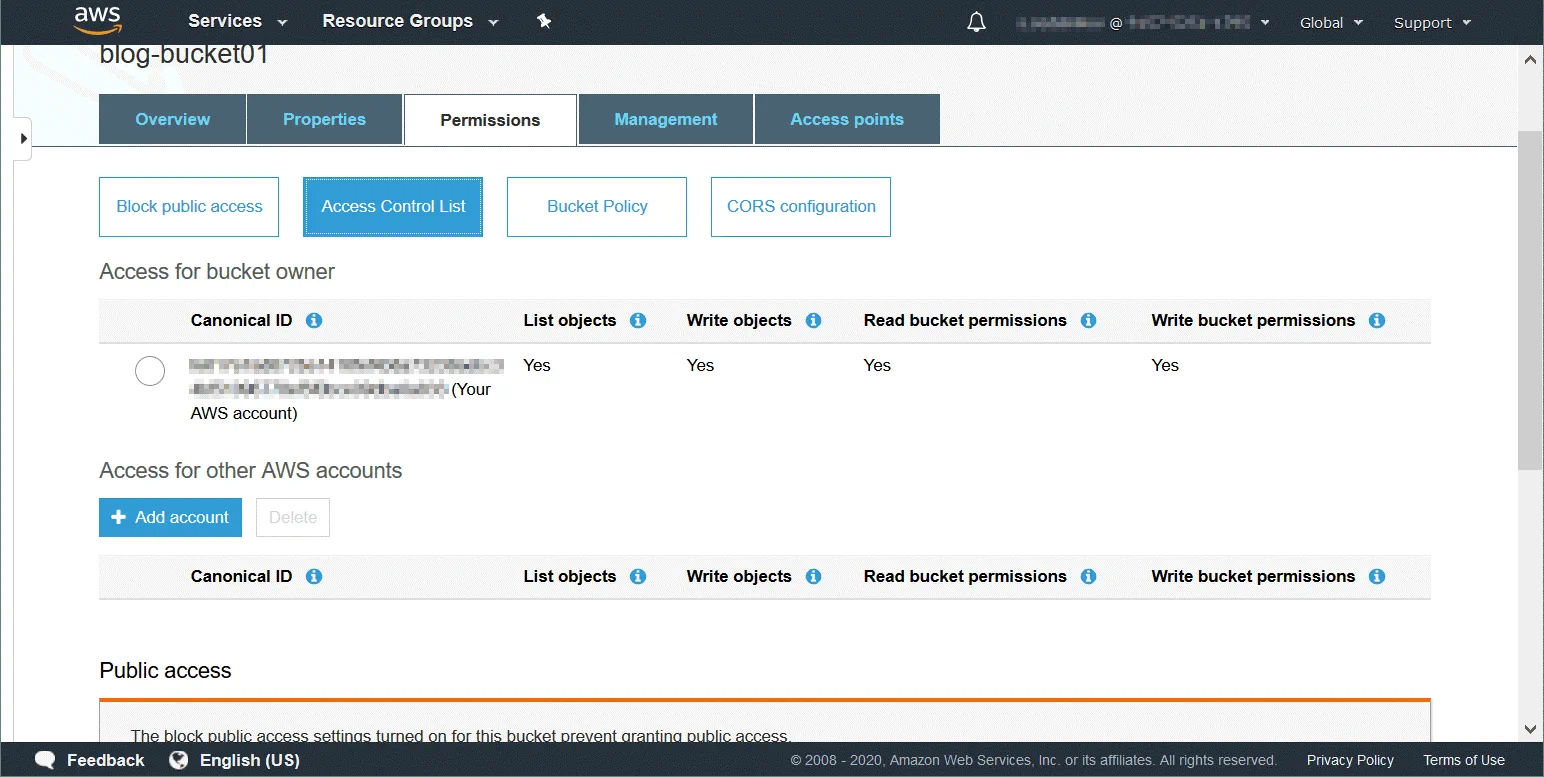
Danh sách kiểm soát truy cập (ACL) là tính năng được sử dụng để quản lý và kiểm soát quyền truy cập vào các đối tượng và bucket. Danh sách kiểm soát truy cập là các chính sách dựa trên tài nguyên được gắn với từng bucket và đối tượng để xác định người dùng và nhóm có quyền truy cập vào bucket và đối tượng đó. Theo mặc định, chủ sở hữu tài nguyên có toàn quyền truy cập vào bucket hoặc đối tượng sau khi tạo tài nguyên. Quyền truy cập bucket xác định ai có thể truy cập các đối tượng trong bucket. Quyền truy cập đối tượng xác định những người dùng được phép truy cập các đối tượng và loại quyền truy cập. Ví dụ: bạn có thể thiết lập quyền chỉ đọc cho một người dùng và quyền đọc-ghi cho một người dùng khác.
Danh sách đầy đủ những người dùng có thể được cấp quyền (người dùng được cấp quyền được gọi là người được cấp quyền):
Owner – người dùng tạo bucket/đối tượng.
Authenticated Users – bất kỳ người dùng nào có tài khoản AWS.
All Users – bất kỳ người dùng nào, bao gồm cả người dùng ẩn danh (người dùng không có tài khoản AWS).
User by Email/Id – một người dùng cụ thể có tài khoản AWS. Địa chỉ email hoặc ID AWS của người dùng phải được chỉ định để cấp quyền truy cập cho người dùng này.
Các loại quyền truy cập có sẵn:
Full Control – loại quyền này cung cấp các quyền Đọc, Ghi, Đọc (ACP) và Ghi ACP.
Read – cho phép liệt kê nội dung thùng chứa khi áp dụng ở cấp độ thùng chứa. Cho phép đọc dữ liệu và siêu dữ liệu của đối tượng khi áp dụng ở cấp độ đối tượng.
Write – chỉ có thể áp dụng ở cấp độ thùng chứa và cho phép tạo, xóa và ghi đè bất kỳ đối tượng nào trong thùng chứa.
Read Permissions (READ ACP) – người dùng có thể đọc quyền truy cập cho đối tượng hoặc thùng chứa được chỉ định.
Write Permissions (WRITE ACP) – người dùng có thể ghi đè quyền truy cập cho đối tượng hoặc thùng chứa được chỉ định. Việc kích hoạt loại quyền này cho người dùng tương đương với việc thiết lập quyền “Full Control” vì người dùng có thể thiết lập bất kỳ quyền nào cho tài khoản của mình. Quyền này được cung cấp mặc định cho chủ sở hữu thùng chứa.
Chính sách thùng chứa
Chính sách thùng chứa là các chính sách quản lý danh tính và truy cập dựa trên tài nguyên của AWS, được sử dụng để tạo các quy tắc điều kiện nhằm cấp quyền truy cập cho các tài khoản và người dùng AWS khi truy cập vào thùng chứa và các đối tượng trong thùng chứa. Bạn có thể sử dụng chính sách thùng chứa để định nghĩa các quy tắc bảo mật cho nhiều đối tượng trong một thùng chứa.
Chính sách thùng chứa được định nghĩa dưới dạng tệp JSON. Văn bản cấu hình chính sách thùng chứa phải tuân thủ các yêu cầu định dạng JSON để hợp lệ. Chính sách thùng chứa chỉ có thể được áp dụng ở cấp độ thùng chứa và được kế thừa cho tất cả các đối tượng trong thùng chứa. Bạn có thể cấp quyền truy cập cho người dùng kết nối từ các địa chỉ IP cụ thể, người dùng của các tài khoản AWS cụ thể, v.v.
Dưới đây là ví dụ về một chính sách cấp quyền truy cập đầy đủ cho tất cả người dùng của một tài khoản và quyền truy cập chỉ đọc cho mọi người dùng của một tài khoản khác. {
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Người dùng có thể truy cập dịch vụ lưu trữ Amazon S3 bằng cách sử dụng các khóa truy cập (Access Key ID và Secret Access Key) mà không cần nhập tên người dùng và mật khẩu. Phương pháp này giúp tăng cường bảo mật và được sử dụng để phát triển các ứng dụng sử dụng API để truy cập dịch vụ lưu trữ đám mây Amazon S3.
API cho Amazon S3
Amazon cung cấp các giao diện lập trình ứng dụng (API) để truy cập các tính năng của S3 và phát triển các ứng dụng riêng cần tương tác với dịch vụ lưu trữ Amazon S3. Amazon cung cấp các giao diện REST và SOAP. Giao diện REST sử dụng các yêu cầu HTTP tiêu chuẩn để làm việc với các bucket và đối tượng. Các tiêu đề HTTP tiêu chuẩn được sử dụng bởi API REST. Giao diện SOAP là một giao diện khác có sẵn. Việc sử dụng SOAP qua HTTP đã bị loại bỏ nhưng bạn vẫn có thể sử dụng SOAP qua HTTPS.
Mô hình thanh toán
Amazon S3 cung cấp mô hình “chỉ trả tiền cho những gì bạn sử dụng”. Không có phí tối thiểu – bạn không cần phải trả tiền cho một lượng lưu trữ và lưu lượng mạng đã định trước. Có các danh mục sử dụng mà bạn phải thanh toán:
Storage. Thanh toán cho các đối tượng được lưu trữ trong Amazon S3. Số tiền bạn phải trả phụ thuộc vào dung lượng lưu trữ đã sử dụng, thời gian lưu trữ các đối tượng trong kho lưu trữ Amazon S3 (trong tháng) và lớp lưu trữ được sử dụng bởi các đối tượng đã lưu trữ.
Requests and data retrieval. Bạn phải thanh toán cho các yêu cầu được thực hiện để truy xuất dữ liệu được lưu trữ trong kho lưu trữ đám mây Amazon S3.
Data transfer. Bạn phải thanh toán cho toàn bộ băng thông đã sử dụng (lưu lượng vào và ra), trừ dữ liệu đến từ internet; dữ liệu ra được chuyển đến các instance Amazon EC2 nằm trong cùng Khu vực AWS với bucket S3 nguồn; dữ liệu ra từ một bucket S3 đến CloudFront.
Management and replication. Bạn phải thanh toán cho việc sử dụng các tính năng quản lý lưu trữ như phân tích và gắn thẻ đối tượng. Amazon tính phí cho việc sao chép giữa các khu vực và sao chép trong cùng khu vực.
Sử dụng Công cụ tính toán Amazon S3 để ước tính chi phí của bạn.



