NAKIVOでIT監視を強化:アラームとレポート機能の解説
組織のインフラストラクチャにIT監視を導入することで、信頼性を高め、深刻な問題、障害、ダウンタイムの発生を防ぐことができます。IT監視の導入には、専用のツールを使用する方法と、ネイティブ機能を活用する方法など、さまざまなアプローチがあります。どちらのアプローチでも、必要に応じて監視データを確認したり、重要なイベントが発生した際に通知を受け取れるよう、自動アラートやレポートを設定したりすることができます。本ブログ記事では、アラートとレポートを活用してIT監視戦略を強化する方法について解説します。
企業におけるIT監視と報告の重要性
IT監視は、ITインフラが適切かつ確実に機能していることを確認する上で不可欠なため、組織にとって極めて重要です。
Maximizing uptime and reliability. 重要な業務システムは通常、24時間365日の稼働が求められます。こうしたシステムは、医療や金融、その他のサービス業界などで利用されており、システム停止は深刻な結果を招く恐れがあります。幸いなことに、IT監視システムを導入し、適切に設定すれば、こうした問題を未然に防ぐことが可能です。事前の問題検知により、管理者はサーバーの過負荷、アプリケーションのエラー、ハードウェアの問題、パフォーマンスの低下といった潜在的な問題を、重大な障害につながる前に早期に発見することができます。この予防的なアプローチにより、管理者はサーバー、仮想マシン(VM)、業務運営、およびエンドユーザーに悪影響が及ぶ前に、適切な対応を講じることができます。潜在的な問題を示すレポートを受け取ることで、IT監視と管理の効率が向上します。
Enhancing securityIT監視は、不正アクセスの試み、異常なネットワークトラフィック、およびサイバー攻撃の兆候となり得るその他の不審な活動を検知するために利用されます。このアプローチにより、管理者はセキュリティ上の脅威を早期に発見することができます。一部の業界では、罰則を回避するためにITシステムの継続的な監視を義務付ける規制要件を遵守しなければなりません。Improving performance and efficiency管理者は、IT監視とアラート設定を行うことで、サーバー、仮想マシン、ネットワーク機器のリソース使用状況を最適化できます。CPU、メモリ、帯域幅の使用状況を追跡し、そのデータを詳細に分析できるようIT監視ツールを設定することで、改善すべき点をより明確に把握できるようになります。その結果、組織はリソースを最適化し、無駄を削減することで、ITシステムの高い効率性を実現できます。また、これにより管理者はボトルネックを特定し、パフォーマンスを向上させることも可能になります。Improving business continuity and disaster recovery. 障害の早期発見は、組織の管理者がIT監視システムに通知機能を設定すべき主な理由の一つです。このアプローチにより、データの破損、アプリケーションのクラッシュ、ハードウェアの故障の兆候を早期に検知し、データ損失を防ぐことができます。データ損失を防ぐことは、 事業継続. 通知設定が済んだ監視ツールを活用することで、管理者はバックアップシステムや災害復旧計画がテストされ、正常に機能していることを確認できます。これにより、災害発生時にも企業がデータやワークロードを迅速に復旧できるという確証が得られます。Improving customer experience. 顧客は、サービスがいつでも利用可能であることを期待しています。サーバー、仮想マシン(VM)、ネットワーク機器、およびウェブサイトの運用に関連するアプリケーションを監視するようIT監視システムを構築することで、ウェブサイトやサービスが常に利用可能な状態を維持することができます。リソースの可用性だけでなく、パフォーマンスも監視することで、最高のサービスを実現します。問題に関する情報が記載された報告を受け取ることで、迅速な解決につながります。これらの報告には、管理者が問題をできるだけ早く解決するために必要な情報が含まれています。こうした対応により、顧客への悪影響を最小限に抑えることができ、結果として顧客は良好な体験を得ることができます。
Cost management. 予防的な監視を設定することで、システム停止を防ぐことができます。予期せぬシステム停止は、収益の損失や、データおよびインフラの復旧にリソースを費やす必要があるため、多大なコストを招く恐れがあります。アラート通知機能を備えた監視システムを利用すれば、管理者は問題を迅速に解決し、システム停止のリスクを低減することができます。
IT監視におけるアラームの理解
IT監視システムのアラームを設定することで、管理者が問題を把握し、より迅速に解決するための対応時間が短縮されます。 グラフや統計情報を表示するWebページなどのリソースのみが設定されている場合、システム管理者は監視情報を含むWebページを確認した時のみ、問題に気付くことができます。管理者は多岐にわたる業務を抱えており、通常、ITインフラの状態を示すWebページを常時監視することはできません。
アラームが設定されている場合、管理者は問題、潜在的な問題、障害、またはその他の重大なイベントや不審なイベントについて、可能な限り速やかに通知メッセージを受け取ることができます。 通常、通知間隔を設定することが可能です。例えば、監視システムが問題を検出した後、1分後または5分後にメッセージを送信するように設定できます。
その結果、システム管理者は問題をより迅速に把握し、問題の修正や悪影響の回避に向けた対応をとることができます。使用するIT監視ソフトウェアに応じて、電子メール、SMS、Skypeなどを通じた通知など、さまざまな通知方法を利用できます。
アラームとは何ですか?また、なぜ重要なのでしょうか?
アラームとは、ITシステムにおいて特定のイベントが発生し、所定の条件や閾値が満たされた際にトリガーされる通知のことです。これらの条件は、以下のようなさまざまなイベントに基づいて設定されます:
Performance issues:CPU使用率の高さ、メモリ不足、応答の遅延Resource thresholds:ディスク容量が不足しています。ネットワーク帯域幅が飽和状態です。System failures:サーバーのクラッシュ、アプリケーションのエラー、サービスの停止Security incidents:不正アクセスの試み、マルウェアの検出、異常なネットワークトラフィックOperational events:バックアップの失敗、サービスの再起動、設定の変更
アラームが作動すると、監視システムがアラートを送信し、このアラートはさまざまな経路を通じて、主にIT管理者を含む関係者に通知されます。これらのアラートには、問題の深刻度、影響を受けたシステムやコンポーネント、推奨される対応策など、問題に関する情報が含まれています。
注視すべき主要指標
CPU utilization. サーバーやシステムに十分な処理能力が確保されているかを確認するには、CPU使用率の監視が必要です。これは、過負荷になることなくワークロードを処理するために重要です。高いCPU使用率は、システムが過負荷になっていることを示す兆候となり得ます。一方、低いCPU使用率は、リソースが十分にあるか、あるいはCPUリソースが十分に活用されていないことを示しています。
Memory (RAM) usageアプリケーションやサービスがスムーズに動作するには十分なメモリが必要であり、この点においてメモリの設定は極めて重要です。管理者は、パフォーマンスの低下やシステムのクラッシュを引き起こす可能性のあるメモリのボトルネックを防ぐため、RAMの使用状況を監視する必要があります。メモリの過剰使用、メモリ割り当ての不足、およびメモリリークに注意を払ってください。
Disk usage and I/O performance. ディスク容量と入出力(I/O)パフォーマンスは、データストレージにおいて極めて重要な指標です。パフォーマンスの問題を含むストレージ関連のトラブルを未然に防ぐため、これらのパラメータを監視することをお勧めします。ディスク使用率の高さ、使用済みディスク容量の急激な増加、データの読み書き時の高レイテンシ、および頻繁なI/O待機時間には特に注意を払ってください。これらのパラメータに異常が見られる場合は、ストレージに問題が発生している可能性を示唆しています。
Network bandwidth and latencyネットワークのパフォーマンスは、コンピュータ、サーバー、仮想マシンがネットワークを介して相互に接続されているため、オフィスやデータセンターにおけるあらゆる業務に影響を及ぼします。ネットワークのパフォーマンスは、顧客に提供するサービスにとって極めて重要です。ネットワークの帯域幅や遅延を監視することで、ボトルネックやその他の問題を早期に検知し、タイムリーに解決することで、ネットワークリソースを効率的に活用することができます。ネットワークの利用率の高さ、パケットロス、遅延の増加には特に注意が必要です。これらは、パフォーマンスの低下やネットワーク接続の問題を示す兆候となるからです。
Service and process availability. 重要なプロセスは、サーバーや仮想マシン上のオペレーティングシステムで実行されており、ビジネスニーズを満たすために常に利用可能でなければなりません。サービスとその可用性を監視することで、重要なサービスが正常に稼働していることを確認できます。サービスの可用性を確保するため、管理者は稼働時間、サービスの再起動頻度、およびプロセスの障害を監視する必要があります。
Database performanceデータベースは、Webアプリケーションを含む、より複雑なソリューションの一部として活用されることがよくあります。さらに、組織内で利用されるソフトウェアソリューションのほとんどは、データベースを必要とします。こうした理由から、データベースのパフォーマンスと可用性を監視することは重要です。データベースを監視することで、データへのアクセスが確保され、関連する操作が円滑に実行されるようになります。データベースを監視する際は、クエリの応答時間、処理に時間がかかるクエリ、データベースのロック、および接続プールの使用状況に重点を置いてください。これらの指標は、データベースの健全性を判断する上で極めて重要です。
IT監視に関するレポート
レポート機能は、監視ツールによって収集された膨大なデータから、体系化された実用的な知見を提供するために使用されます。レポートは、生データを、組織内の関係者、特にIT管理者にとって読みやすく理解しやすい情報へと変換します。レポートを確認した後、管理者や経営陣は十分な情報に基づいた意思決定を行うことができます。これにより、ITチームはパフォーマンスの最適化、問題の未然防止、および事業継続性の向上を図ることができます。
のレポートは、アラームを調査しているだけでは気づきにくい異常を浮き彫りにすることができます。 レポート内のデータは、主要な指標を手動で検索したり収集したデータを整理したりする手間を省くため、利便性を高めるべく集計されています。その結果、管理者はインフラ全体および最も重要なコンポーネントの概要を俯瞰的に把握できます。インシデント発生に至る状況に関する情報を把握しておくことで、管理者は迅速なインシデント対応や予防措置の実施に役立てることができます。
~による監視 NAKIVO Backup & Replication
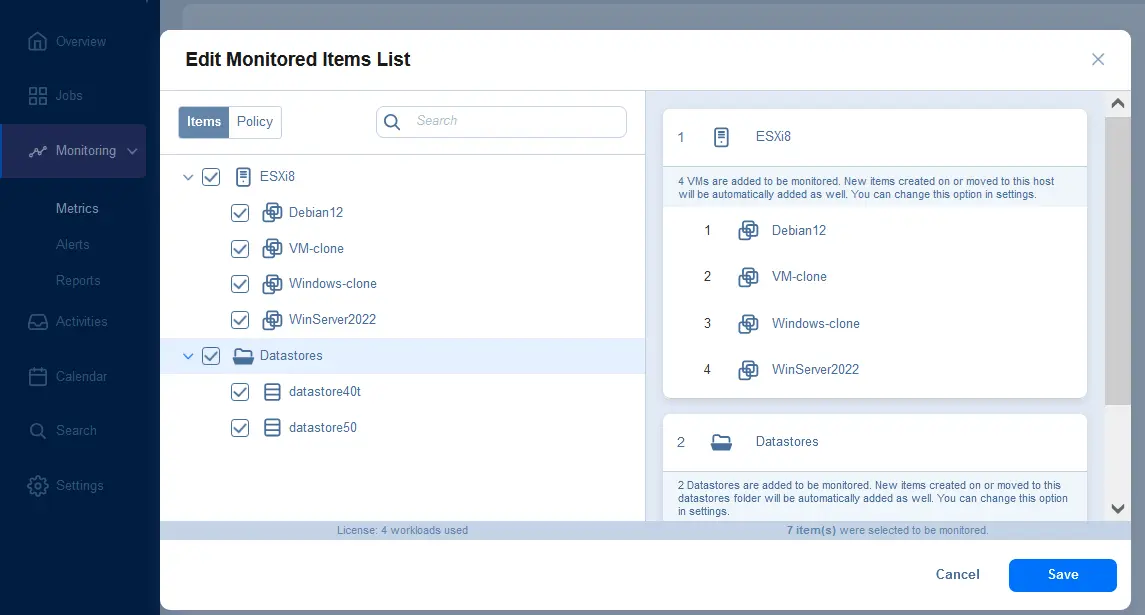
NAKIVO Backup & Replication ITインフラストラクチャの各要素を監視するのに役立ちます。以下のページにアクセスしてください。 Monitoring Webインターフェースの該当セクションで、監視対象項目を追加し、サポートされているメトリクスを表示するグラフを確認します。 VMware vSphere インフラ。

ESXiホストなどの監視対象を選択できます。 クラスター、VMware VM、およびデータストア Monitoring > Metrics.
NAKIVOソリューションにおけるアラームの設定
NAKIVOソリューションではアラートを設定することで、潜在的な問題についていち早く通知を受け取ることができ、深刻な事態に発展する前に迅速に対処することが可能になります。
- 移動
Monitoring>Alerts、を選択してAlert Template Managementタブをクリックし、+特定のアイテムにアラートを追加するには。
- アラートをトリガーする監視対象を選択してください。ESXiホスト、仮想マシン(VM)、またはデータストアを選択できます。クリック
Next続きを読む。
- 新しいアラートテンプレートのルールを設定します。[クリック]
+そして、ルールの条件を選択します。たとえば、ホストの平均メモリ使用率が1時間にわたって90%を超えた場合にトリガーされるアラートルールテンプレートを設定できます。1つのアラートテンプレートに対して複数のルールを追加することができます。
- アラートテンプレートの設定を行います。アラート名と説明を入力し、重大度を選択します。チェックボックスをオンにすると、
send an email notification when this alert is triggeredそして、アラート通知を受け取る受信者のメールアドレスを複数入力してください。クリックFinish.
NAKIVOソリューションでのレポートの設定
- レポートを設定するには、次の場所へ移動してください
Monitoring>Reports、クリック+そしてクリックReport.
- サポートされているソースタイプの中から1つを選択できます:
- インフラストラクチャの概要 – vCenterサーバー、vCenterによって管理されるESXiホスト、およびスタンドアロンのESXiホストに関する情報
- VMのパフォーマンス
- データストアの容量
- ホストのパフォーマンス
- 保護レポート
ソースの種類を選択したら、レポートに含める項目を選択します。下のスクリーンショットでは、
Infrastructure Overviewドロップダウンリストから選択し、レポートに含めるESXiホストを選択します。[クリック]Next続きを読む。
- レポートの日時範囲を設定します。たとえば、過去30日間のレポートを作成することができます。

- レポートの設定を行います。表示されるレポート名と説明を入力します。必要に応じて、
Notificationsセクションで、チェックボックスを選択して、指定したメールアドレスにレポートを送信します。メールアドレスを入力し、Enterこのメールアドレスを登録するには。複数のメールアドレスを入力できます。クリックFinishレポート作成の設定を保存するには。
- レポートをファイルにエクスポートできます。次の手順に従ってください。
Monitoring>Reportsエクスポートしたいレポートを選択します(チェックボックスにチェックを入れます)。[…"その他のオプション"ボタンをクリックExport、そしてダイアログボックスでファイル形式(PDF または CSV)を選択します。クリックExport.
結論
ITインフラの監視は、管理効率の向上、事業継続性の確保、およびコスト削減につながります。潜在的な問題を未然に防ぎ、既存の問題をできるだけ早く解決するために、インシデントへの早期対応が可能なよう、アラートやレポートを送信する設定をIT監視ツールに行うことをお勧めします。使用 NAKIVO Backup & Replication VMware仮想マシンを含むデータを保護し、vSphereインフラストラクチャおよびデータ保護ジョブを監視します。



